PennyLaneでアヤメのデータを2値分類する
機械学習でアヤメの分類を行います。
前回ステップ3まで実行したのでステップ4、ステップ5までを行ってみます。
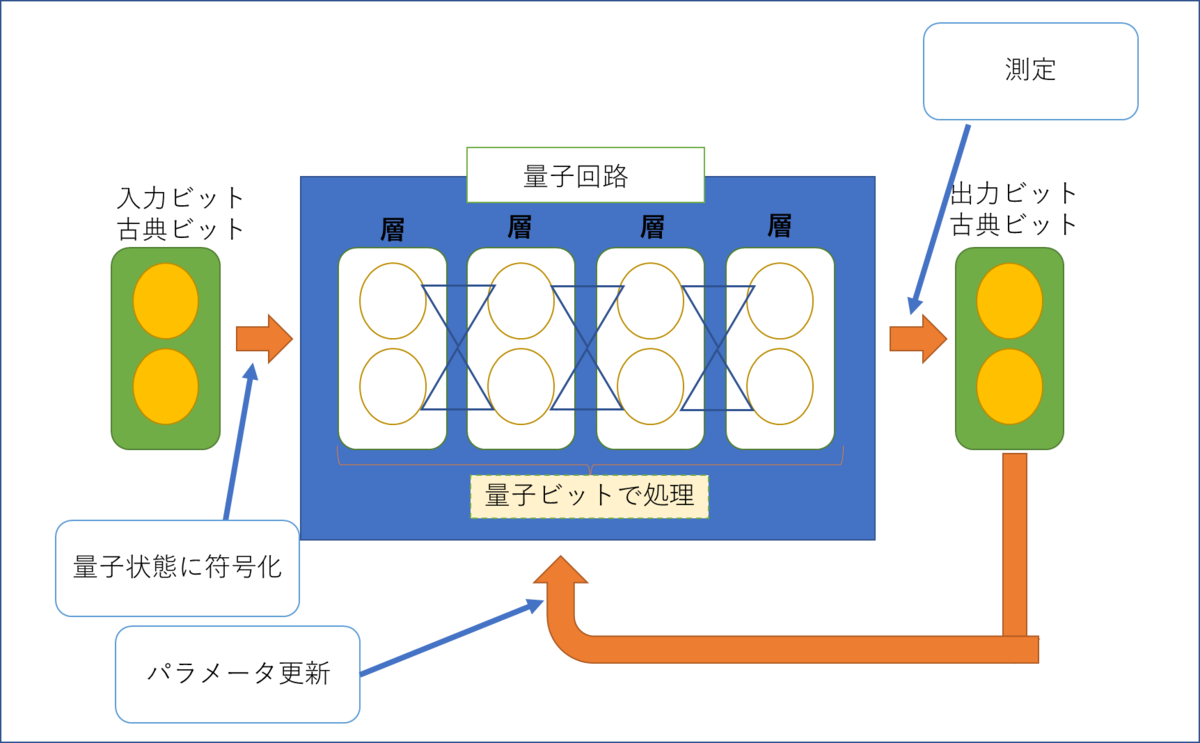
ステップ4:出力データを処理し、損失関数の値を求める部分を実装
出力データを処理し、損失間の値を求めるために必要はメソッドの実装を行います。
実装内容は以下の通りです。
①損失間の値を計算(平均2条誤差を利用)
②推定の精度を計算
③量子回路の実行結果にパラメータbiasを加える
④出力データを処理し、損失間の値を求める流れを実行
①損失間の値を計算(平均2条誤差を利用)
正解ラベルの値と予測値の平均2条誤差
def square_loss(labels, predictions):
loss = 0
for l, p in zip(labels, predictions):
loss = loss + (l - p) ** 2
loss = loss / len(labels)
return loss
②推定の精度を計算
正解ラベルと推定値ラベルを比較して、1e-5の精度で一致した場合は正しく分類できたと推定。
そして、正しく判定した確率を計算
def accuracy(labels, predictions):
loss = 0
for l, p in zip(labels, predictions):
if abs(l - p) < 1e-5:
loss = loss + 1
loss = loss / len(labels)
return loss
③量子回路の実行結果にパラメータbiasを加える
def variational_classifier(weights, bias, angles):
return circuit(weights, angres) + bias
④出力データを処理し、損失間の値を求める流れを実行
def cost(weights, bias, fratures, labels):
predictions = [variational_classifier(weights, bias, f) for f in features]
return square_loss(labels, predictions)
ステップ5:学習処理を実装
・実装する内容
①Irisのデータを学習データと検証データに分類とパラメータ初期化
②学習処理の実装
①Irisのデータを学習データと検証データに分類
60回実行します。
from pennylane.optimize import NesterovMomentumOptimizer
opt = NesterovMomentumOptimizer(0.01)
batch_size = 5
weights = weights_init
bias = bias_init
for it in range(60):
# Update the weights by one optimizer step
batch_index = np.random.randint(0, num_train, (batch_size))
feats_train_batch = feats_train[batch_index]
Y_train_batch = Y_train[batch_index]
# 量子回路の実行
weights, bias, _, _ = opt.step(cost, weights, bias, feats_train_batch,Y_train_batch)
# 学習データに対する精度を求める
#検証データに対する精度を求める
acc_train = accuracy(Y_train,predictions_train)
acc_val = accuracy(Y_val,prediction_val)
print(
"Iter: {:5d} | Cost: {:0.7f} | Acc_train: {:0.7f} | Acc_validation: {:0.7f} "
"".format(it + 1, cost(weights, bias, features, Y), acc_train,acc_val)
)
実行結果
待つこと数分。。
検証データに対して100%の確立で2値分類できました。(Acc valiationの値が1.00・・)

この先を学ぶためのおすすめサイトとして以下が紹介されていました。
ご参考まで。